Training Course on Unsupervised Learning Techniques
Training Course on Unsupervised Learning Techniques delves into the core principles and practical applications of algorithms that identify hidden patterns, group similar data points, and reduce dimensionality
Skills Covered
Course Overview
Training Course on Unsupervised Learning Techniques
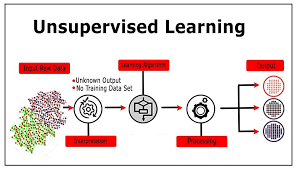
Introduction
Unlock the power of unlabeled data with our comprehensive training course on Unsupervised Learning Techniques. In today's data-rich environment, the ability to extract meaningful insights without explicit guidance is a crucial skill. This course delves into the core principles and practical applications of algorithms that identify hidden patterns, group similar data points, and reduce dimensionality. Master essential techniques such as clustering algorithms, including K-Means and DBSCAN, dimensionality reduction methods like Principal Component Analysis (PCA) and t-SNE, and association rule mining to uncover valuable relationships within your datasets. Equip yourself with the knowledge and hands-on experience to drive data-driven decisions and gain a competitive edge by leveraging the untapped potential of your unstructured data.
This intensive program provides a blend of theoretical understanding and practical implementation, ensuring you can confidently apply these techniques to real-world challenges. Through engaging lectures, interactive exercises, and real-case studies, you will gain proficiency in using industry-standard tools and libraries. By the end of this course, you will be able to select the appropriate unsupervised learning technique for different data types and business problems, evaluate model performance, and effectively communicate your findings. Elevate your data science capabilities and become a proficient practitioner of unsupervised machine learning.
Course Duration
5 days
Course Objectives
- Understand the fundamental concepts and principles of unsupervised learning.
- Differentiate between supervised, unsupervised, and reinforcement learning paradigms.
- Apply various clustering techniques such as K-Means, Hierarchical Clustering, and DBSCAN.
- Evaluate the performance of clustering algorithms using appropriate metrics.
- Implement dimensionality reduction techniques like PCA and t-SNE for data visualization and preprocessing.
- Utilize association rule mining algorithms to discover relationships in data.
- Explore anomaly detection methods using unsupervised learning.
- Learn to preprocess and prepare unlabeled datasets for unsupervised learning tasks.
- Gain practical experience using Python libraries such as scikit-learn for implementing unsupervised models.
- Understand the applications of unsupervised learning in various domains like customer segmentation and image analysis.
- Select the most suitable unsupervised learning model for a given problem and dataset.
- Interpret and communicate the results of unsupervised learning models effectively.
- Stay updated with the latest trends and advancements in the field of unsupervised AI.
Organizational Benefits
- Identify hidden patterns and valuable insights from unstructured data.
- Improve customer segmentation for more targeted marketing campaigns.
- Detect anomalies and outliers for fraud detection and risk management.
- Reduce data dimensionality for efficient storage and faster processing.
- Discover associations and relationships between data points for market basket analysis.
- Enhance data exploration and visualization capabilities.
- Gain a competitive advantage through data-driven decision-making based on AI-powered insights.
- Empower employees with advanced data analysis skills.
Target Audience
- Data Scientists
- Data Analysts
- Machine Learning Engineers
- Business Analysts
- IT Professionals
- Researchers
- Students in relevant fields (Computer Science, Statistics, etc.)
- Anyone interested in extracting insights from data without labels
Training Outline
Module 1: Introduction to Unsupervised Learning
- Defining Unsupervised Learning and its significance.
- Contrasting Unsupervised Learning with Supervised and Reinforcement Learning.
- Real-world applications of Unsupervised Learning across industries.
- Ethical considerations and potential challenges in Unsupervised Learning.
- Overview of the different types of Unsupervised Learning techniques.
Module 2: Clustering Techniques
- Understanding the concept of clustering and its objectives.
- K-Means Clustering: Algorithm, implementation, and limitations.
- Hierarchical Clustering: Agglomerative and divisive approaches.
- Density-Based Clustering (DBSCAN): Identifying clusters of arbitrary shapes.
- Evaluating clustering performance using metrics like Silhouette Score and Davies-Bouldin Index.
Module 3: Dimensionality Reduction
- The curse of dimensionality and its impact on machine learning.
- Principal Component Analysis (PCA): Concepts, application, and interpretation.
- t-distributed Stochastic Neighbor Embedding (t-SNE): For visualizing high-dimensional data.
- Linear Discriminant Analysis (LDA) as a supervised dimensionality reduction technique (for context).
- Applications of dimensionality reduction in data preprocessing and visualization.
Module 4: Association Rule Mining
- Understanding market basket analysis and association rules.
- Apriori Algorithm: Finding frequent itemsets and generating association rules.
- Support, Confidence, and Lift: Metrics for evaluating association rules.
- Applications of association rule mining in retail, e-commerce, and other domains.
- Challenges and considerations in association rule mining.
Module 5: Anomaly Detection
- Identifying outliers and anomalies in datasets.
- Statistical methods for anomaly detection (e.g., Z-score, IQR).
- Unsupervised learning-based anomaly detection techniques (e.g., Isolation Forest, One-Class SVM).
- Applications of anomaly detection in fraud detection, intrusion detection, and quality control.
- Evaluating the performance of anomaly detection models.
Module 6: Model Selection and Evaluation
- Choosing the right unsupervised learning technique for a given problem.
- Understanding the importance of data preprocessing for unsupervised learning.
- Evaluating the performance of different unsupervised learning models.
- Techniques for parameter tuning in unsupervised learning algorithms.
- Best practices for interpreting and presenting the results of unsupervised learning.
Module 7: Practical Implementation with Python
- Introduction to relevant Python libraries (e.g., scikit-learn, pandas, numpy, matplotlib, seaborn).
- Hands-on exercises on implementing clustering algorithms in Python.
- Practical examples of applying dimensionality reduction techniques.
- Implementing association rule mining using Python libraries.
- Building anomaly detection models using Python.
Module 8: Advanced Topics and Future Trends
- Overview of other unsupervised learning techniques (e.g., Autoencoders, Generative Adversarial Networks - GANs for unsupervised tasks).
- Scalability and handling large datasets in unsupervised learning.
- Integrating unsupervised learning with other machine learning techniques.
- Ethical implications and responsible use of unsupervised learning.
- Emerging trends and future directions in unsupervised learning research and applications.
Training Methodology
This course will employ a blended learning approach, combining:
- Interactive Lectures: Covering the theoretical foundations and concepts.
- Practical Demonstrations: Illustrating the implementation of techniques using Python.
- Hands-on Exercises: Providing opportunities for learners to apply the concepts and code themselves.
- Case Studies: Analyzing real-world scenarios and applying unsupervised learning to solve problems.
- Group Discussions: Facilitating peer learning and knowledge sharing.
Register as a group from 3 participants for a Discount
Send us an email: info@datastatresearch.org or call +254724527104
Certification
Upon successful completion of this training, participants will be issued with a globally- recognized certificate.
Tailor-Made Course
We also offer tailor-made courses based on your needs.
Key Notes
a. The participant must be conversant with English.
b. Upon completion of training the participant will be issued with an Authorized Training Certificate
c. Course duration is flexible and the contents can be modified to fit any number of days.
d. The course fee includes facilitation training materials, 2 coffee breaks, buffet lunch and A Certificate upon successful completion of Training.
e. One-year post-training support Consultation and Coaching provided after the course.
f. Payment should be done at least a week before commence of the training, to DATASTAT CONSULTANCY LTD account, as indicated in the invoice so as to enable us prepare better for you.